Publications
2025
-
 FDAL: Leveraging Feature Distillation for Efficient and Task-Aware Active LearningRebati Gaire, and Arman RoohiIn Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025
FDAL: Leveraging Feature Distillation for Efficient and Task-Aware Active LearningRebati Gaire, and Arman RoohiIn Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025Active learning (AL) offers a promising strategy for reducing annotation costs by selectively querying informative samples. However, its deployment on edge devices remains fundamentally limited. In such resource-constrained environments, models must be highly compact to meet strict compute, memory, and energy budgets. These lightweight models, though efficient, suffer from limited representational capacity and are ill-equipped to support existing AL methods, which assume access to high-capacity networks capable of modeling uncertainty or learning expressive acquisition functions. To address this, we introduce FDAL, a unified framework that couples task-aware AL with feature-distilled training to enable efficient and accurate learning on resource-limited devices. A task-aware sampler network, trained adversarially alongside a lightweight task model, exploits refined features from feature distillation to prioritize informative unlabeled instances for annotation. This joint optimization strategy ensures tight coupling between task utility and sampling efficacy. Extensive experiments on SVHN, CIFAR-10, and CIFAR-100 demonstrate that FDAL consistently outperforms state-of-the-art AL methods, achieving competitive accuracy with significantly fewer labels under limited compute and annotation budgets. Notably, FDAL achieves 78.5% accuracy on CIFAR-10 with only 30% labeled data, matching the fully supervised baseline of 78.38%. The code is made publicly available at https://github.com/rrgaire/FDAL for reproducibility and future research.
@inproceedings{gaire2025fdal, title = {FDAL: Leveraging Feature Distillation for Efficient and Task-Aware Active Learning}, author = {Gaire, Rebati and Roohi, Arman}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision}, pages = {3131--3138}, year = {2025}, google_scholar_id = {ufrVoPGSRksC}, } -
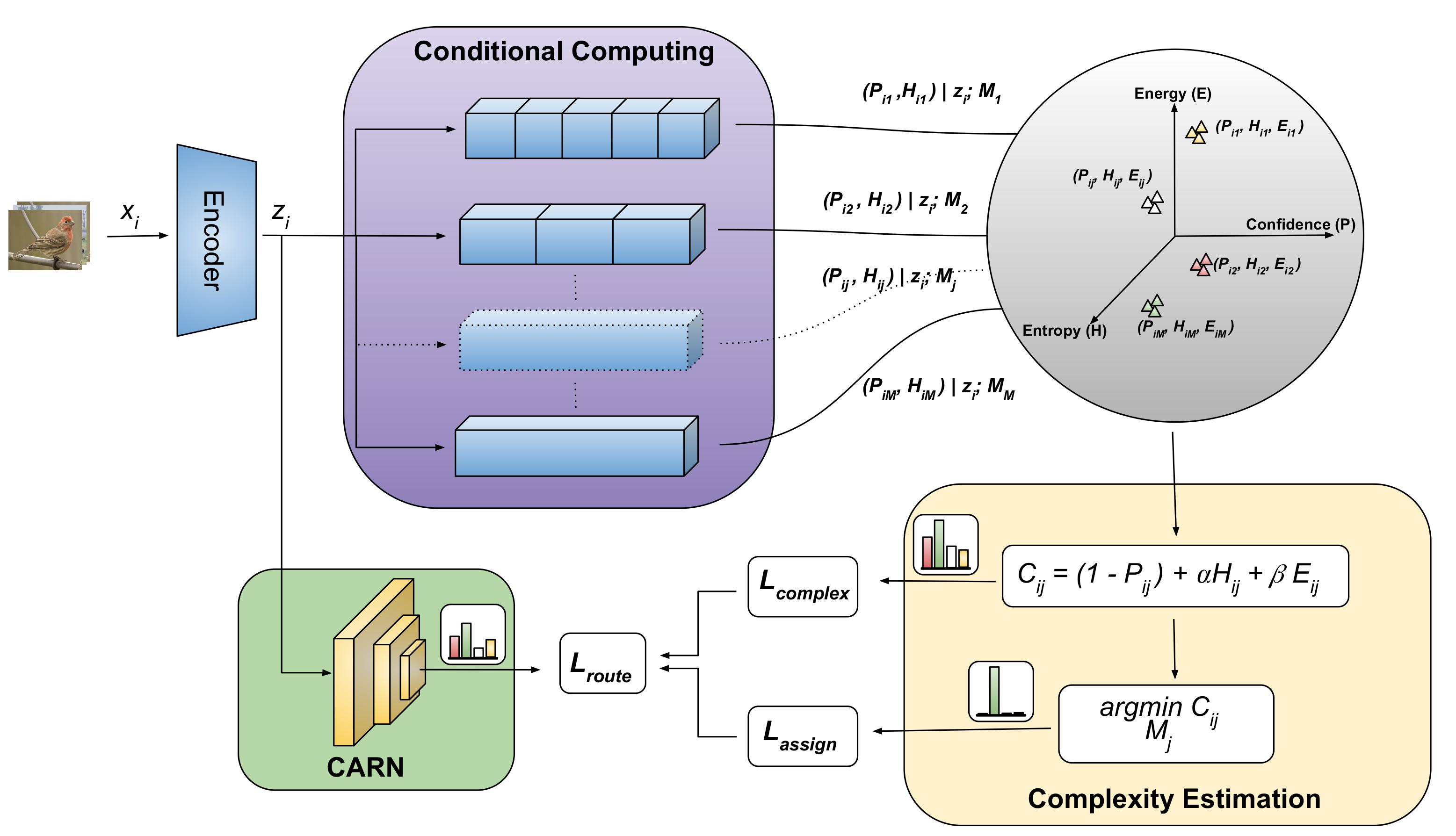 CARN: Complexity-Aware Routing Network for Efficient and Adaptive InferenceRebati Gaire, and Arman RoohiIn Proceedings of the Computer Vision and Pattern Recognition Conference, 2025
CARN: Complexity-Aware Routing Network for Efficient and Adaptive InferenceRebati Gaire, and Arman RoohiIn Proceedings of the Computer Vision and Pattern Recognition Conference, 2025Deep neural networks (DNNs) have achieved remarkable success across various domains, yet their rigid, static computation graphs lead to significant inefficiencies in real-world deployment. Standard architectures allocate equal computational resources to all inputs, disregarding their inherent complexity, which results in unnecessary computation for simple samples and suboptimal processing for complex ones. To address this, we propose the Complexity-Aware Routing Network (CARN), a novel framework that dynamically adjusts computational pathways based on input complexity. CARN integrates a self-supervised complexity estimation module that quantifies input difficulty using confidence, entropy, and computational cost, guiding a neural network-based routing mechanism to optimally assign task modules. The model is trained using a routing loss function that balances assignment accuracy and computational efficiency, mitigating expert starvation while preserving specialization. Extensive experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet demonstrate that CARN achieves up to 4x reduction in computational cost and over 10x reduction in parameter movement while maintaining high accuracy compared to state-of-the-art static models. The code and pre-trained models are made available at https://github.com/rrgaire/CARN for reproducibility and further research.
@inproceedings{gaire2025carn, title = {CARN: Complexity-Aware Routing Network for Efficient and Adaptive Inference}, author = {Gaire, Rebati and Roohi, Arman}, booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference}, pages = {3318--3326}, year = {2025}, google_scholar_id = {WF5omc3nYNoC}, }


2024
-
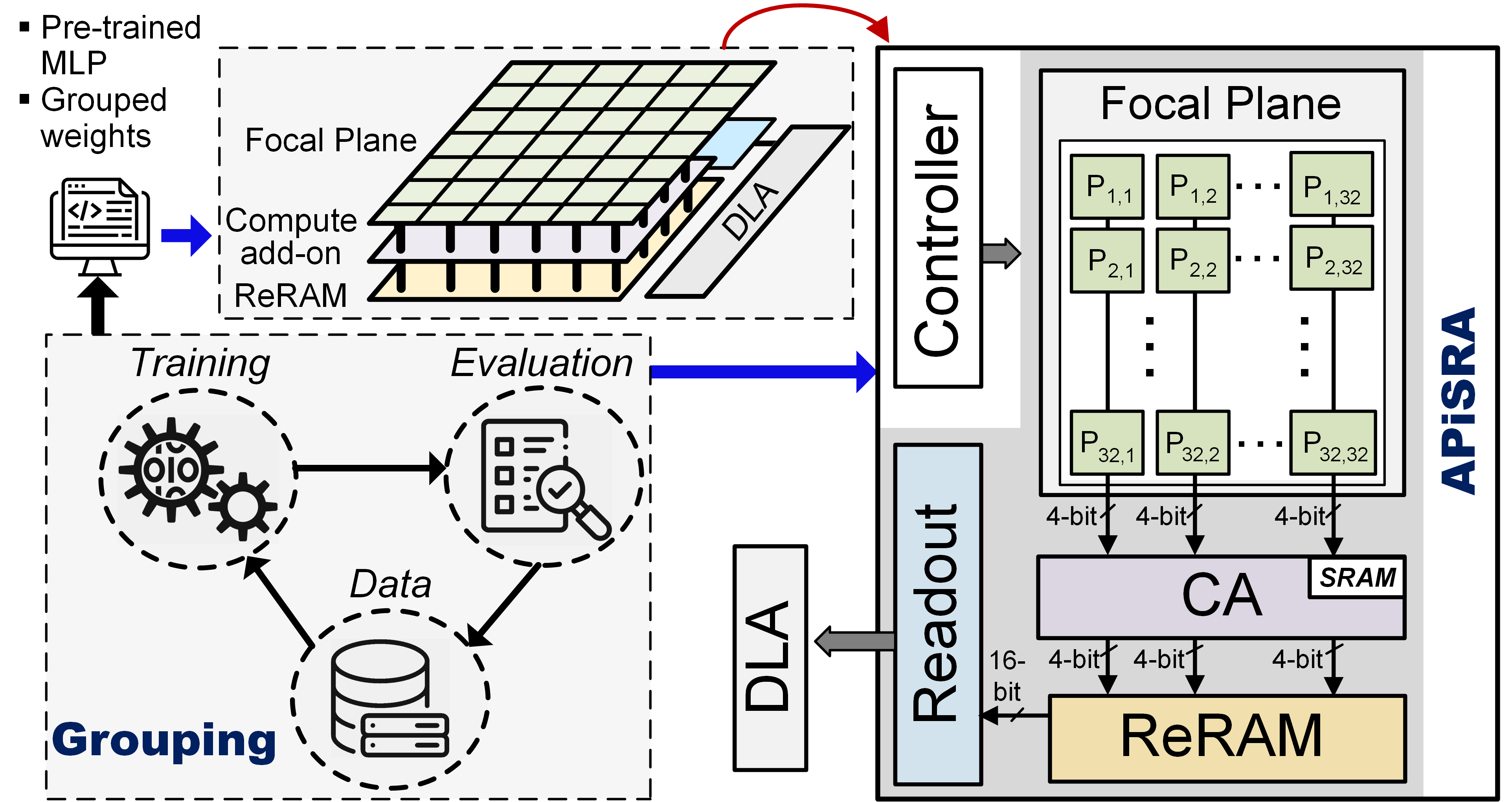 APRIS: Approximate Processing ReRAM In-Sensor Architecture Enabling Artificial-Intelligence-Powered EdgeSepehr Tabrizchi, Rebati Gaire, Mehrdad Morsali, and 4 more authorsIEEE Transactions on Emerging Topics in Computing, 2024
APRIS: Approximate Processing ReRAM In-Sensor Architecture Enabling Artificial-Intelligence-Powered EdgeSepehr Tabrizchi, Rebati Gaire, Mehrdad Morsali, and 4 more authorsIEEE Transactions on Emerging Topics in Computing, 2024Artificial-intelligence-powered edge devices are inspiring interest in always-on, intelligent, and self-powered visual perception systems. Due to the high energy cost of converting raw data and the limited computing and energy resources available, designing energy-efficient and low bandwidth CMOS vision sensors is vital as these emerging systems require continuous sensing and instant processing. This paper proposes a low-power integrated sensing and computing engine, namely APRIS, including a novel software/hardware co-design technique. This method provides a highly parallel analog multiplication and accumulation-in-pixel scheme, which realizes low-precision quantized weight neural networks to mitigate the overhead of analog-to-digital converters and analog buffers. Moreover, in order to reduce the size and power consumption, we propose the implementation of an approximate ADC in the readout circuit. Our system utilizes eight memory banks to increase computation parallelism, which has a dramatic effect on its speed and efficiency. Moreover, the proposed structure supports a zero-skipping scheme to reduce power consumption further. Our circuit-to-application co-simulation results demonstrate a comparable accuracy for our platform to the full-precision baseline on various object classification tasks while reaching an efficiency of 3.48 TOp/s/W.
@article{tabrizchi2024apris, title = {APRIS: Approximate Processing ReRAM In-Sensor Architecture Enabling Artificial-Intelligence-Powered Edge}, author = {Tabrizchi, Sepehr and Gaire, Rebati and Morsali, Mehrdad and Liehr, Maximilian and Cady, Nathaniel and Angizi, Shaahin and Roohi, Arman}, journal = {IEEE Transactions on Emerging Topics in Computing}, year = {2024}, publisher = {IEEE}, google_scholar_id = {W7OEmFMy1HYC} } -
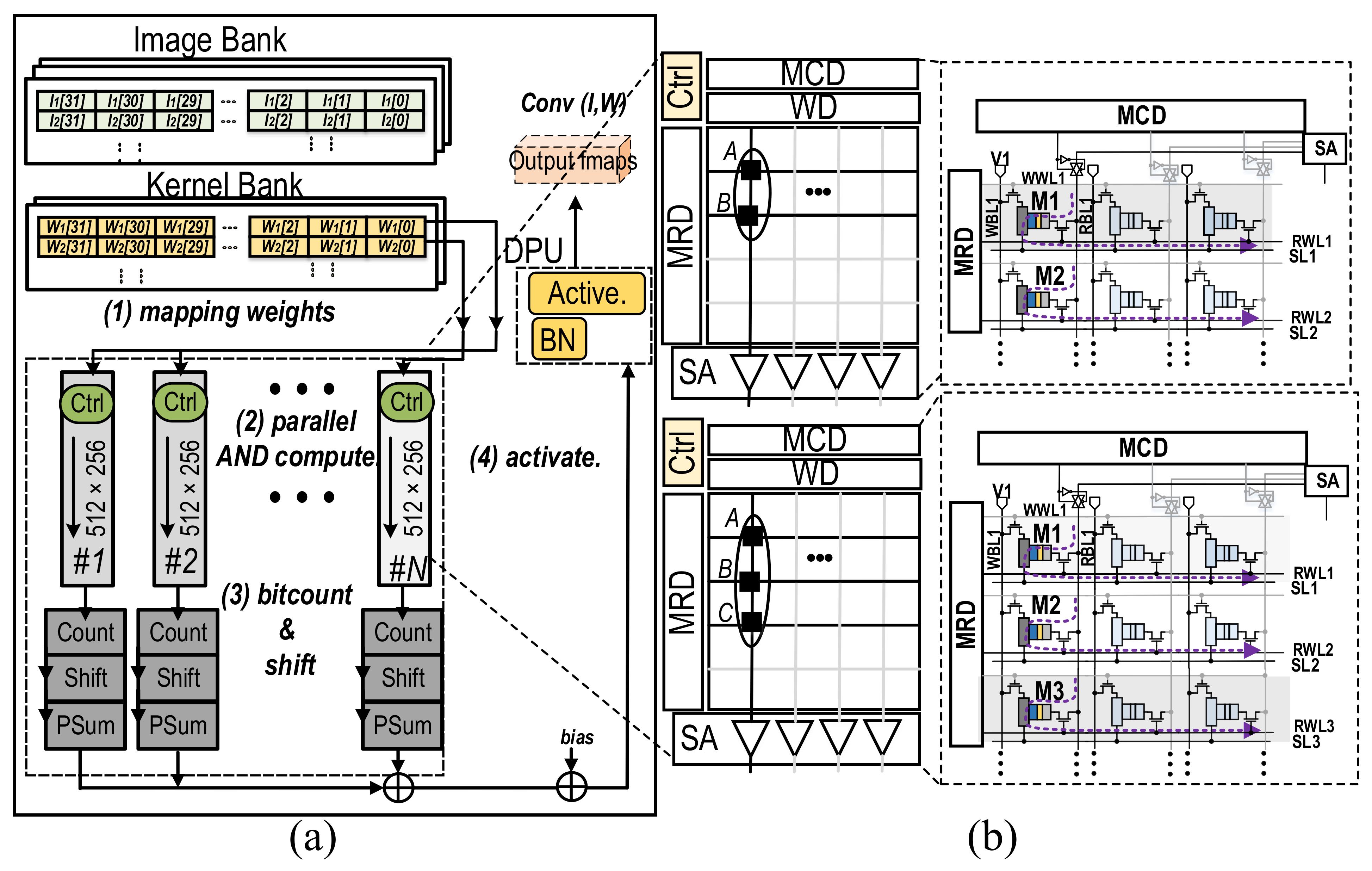 DECO: Dynamic Energy-aware Compression and Optimization for In-Memory Neural NetworksRebati Gaire, Sepehr Tabrizchi, Deniz Najafi, and 2 more authorsIn 2024 IEEE 67th International Midwest Symposium on Circuits and Systems (MWSCAS), 2024
DECO: Dynamic Energy-aware Compression and Optimization for In-Memory Neural NetworksRebati Gaire, Sepehr Tabrizchi, Deniz Najafi, and 2 more authorsIn 2024 IEEE 67th International Midwest Symposium on Circuits and Systems (MWSCAS), 2024This paper introduces DECO, a framework that combines model compression and processing-in-memory (PIM) to improve the efficiency of neural networks on IoT devices. By integrating these technologies, DECO significantly reduces energy consumption and operational latency through optimized data movement and computation, demonstrating notable performance gains on CIFAR-10/100 datasets. The DECO learning framework significantly improved the performance of compressed network modules derived from MobileNetV1 and VGG16, with accuracy gains of 1.66 % and 0.41 %, respectively, on the intricate CIFAR-100 dataset. DECO outperforms the GPU implementation by a significant margin, demonstrating up to a two-order-of-magnitude increase in speed based on our experiment.
@inproceedings{gaire2024deco, title = {DECO: Dynamic Energy-aware Compression and Optimization for In-Memory Neural Networks}, author = {Gaire, Rebati and Tabrizchi, Sepehr and Najafi, Deniz and Angizi, Shaahin and Roohi, Arman}, booktitle = {2024 IEEE 67th International Midwest Symposium on Circuits and Systems (MWSCAS)}, pages = {1441--1445}, year = {2024}, organization = {IEEE}, google_scholar_id = {Y0pCki6q_DkC} } -
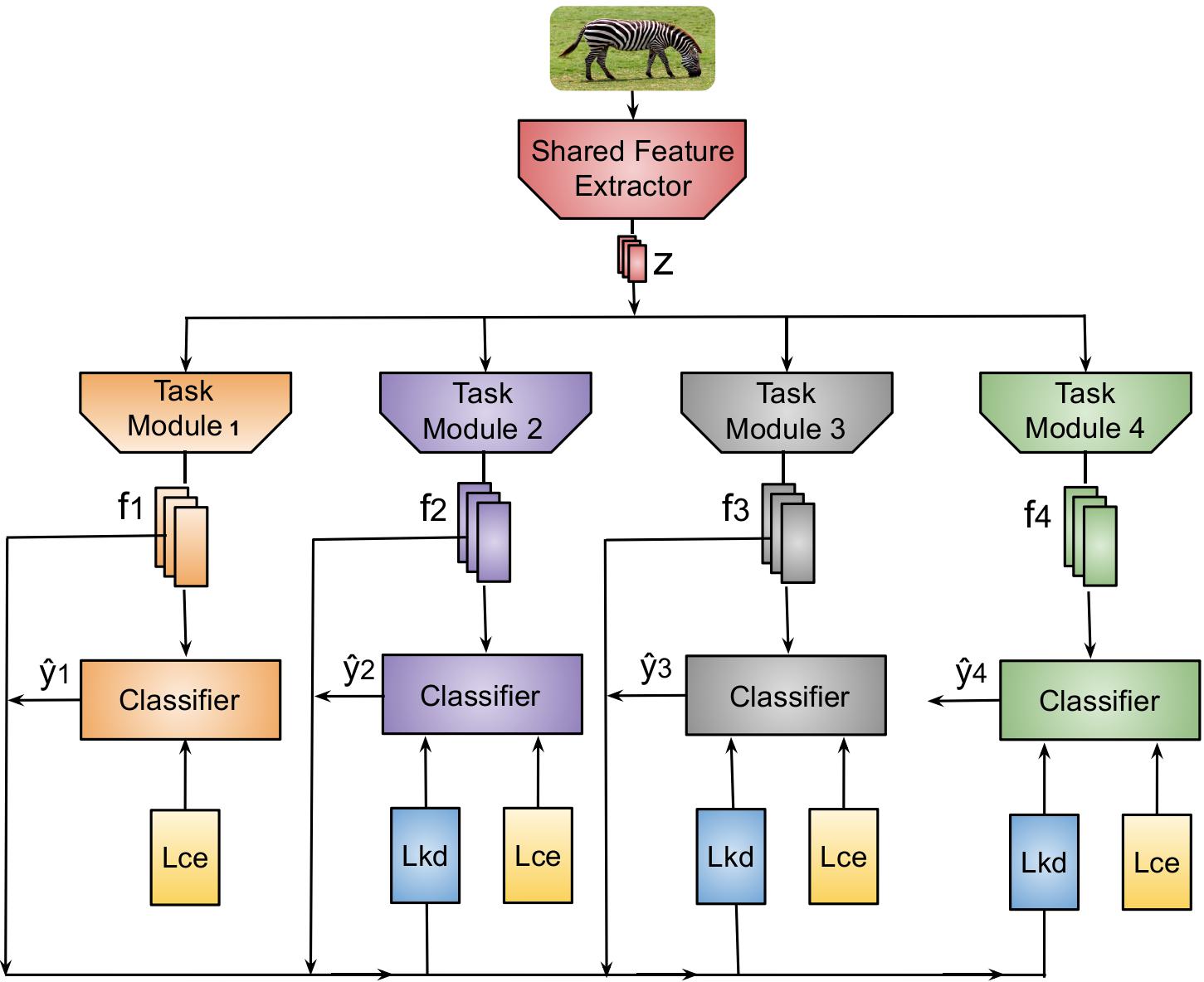 Resource-efficient adaptive-network inference framework with knowledge distillation-based unified learningRebati Gaire, Sepehr Tabrizchi, and Arman RoohiIn 2024 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), 2024
Resource-efficient adaptive-network inference framework with knowledge distillation-based unified learningRebati Gaire, Sepehr Tabrizchi, and Arman RoohiIn 2024 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), 2024Batteryless edge devices represent a promising av-enue for sustainable computing, but are challenged by intermittent behavior and energy constraints. To address these issues, we propose a novel comprehensive approach integrating adaptive task module selection for intermittent computing paradigms. Our methodology incorporates the design of diverse task modules with varying sizes, precision levels, computational requirements, and energy consumption profiles, utilizing various compression techniques. These modules utilize a shared feature extractor that minimizes data movement and facilitates efficient checkpoint recovery, enhancing overall system robustness. In computing mode, the employed power-aware scheduler selects task modules based on performance requirements and available energy in the system. Subsequently, computation is performed to ensure optimal resource utilization while meeting application demands. We ensure optimal performance of these modules with proposed knowledge distillation-based unified learning. Quantitative evaluations on benchmark datasets-CIFAR-10, CIFAR-100, and Tiny-ImageNet-reveal that, with our proposed learning framework, designed models not only achieve improved performance metrics, including accuracy increases of 1.47%, 2.44%, and 3.70% for each dataset respectively but also enhance energy efficiency. These results validate our comprehensive and synergistic approach, demonstrating significant gains in both performance and resource optimization.
@inproceedings{gaire2024resource, title = {Resource-efficient adaptive-network inference framework with knowledge distillation-based unified learning}, author = {Gaire, Rebati and Tabrizchi, Sepehr and Roohi, Arman}, booktitle = {2024 IEEE Computer Society Annual Symposium on VLSI (ISVLSI)}, pages = {508--513}, year = {2024}, organization = {IEEE}, google_scholar_id = {Tyk-4Ss8FVUC}, }



2023
-
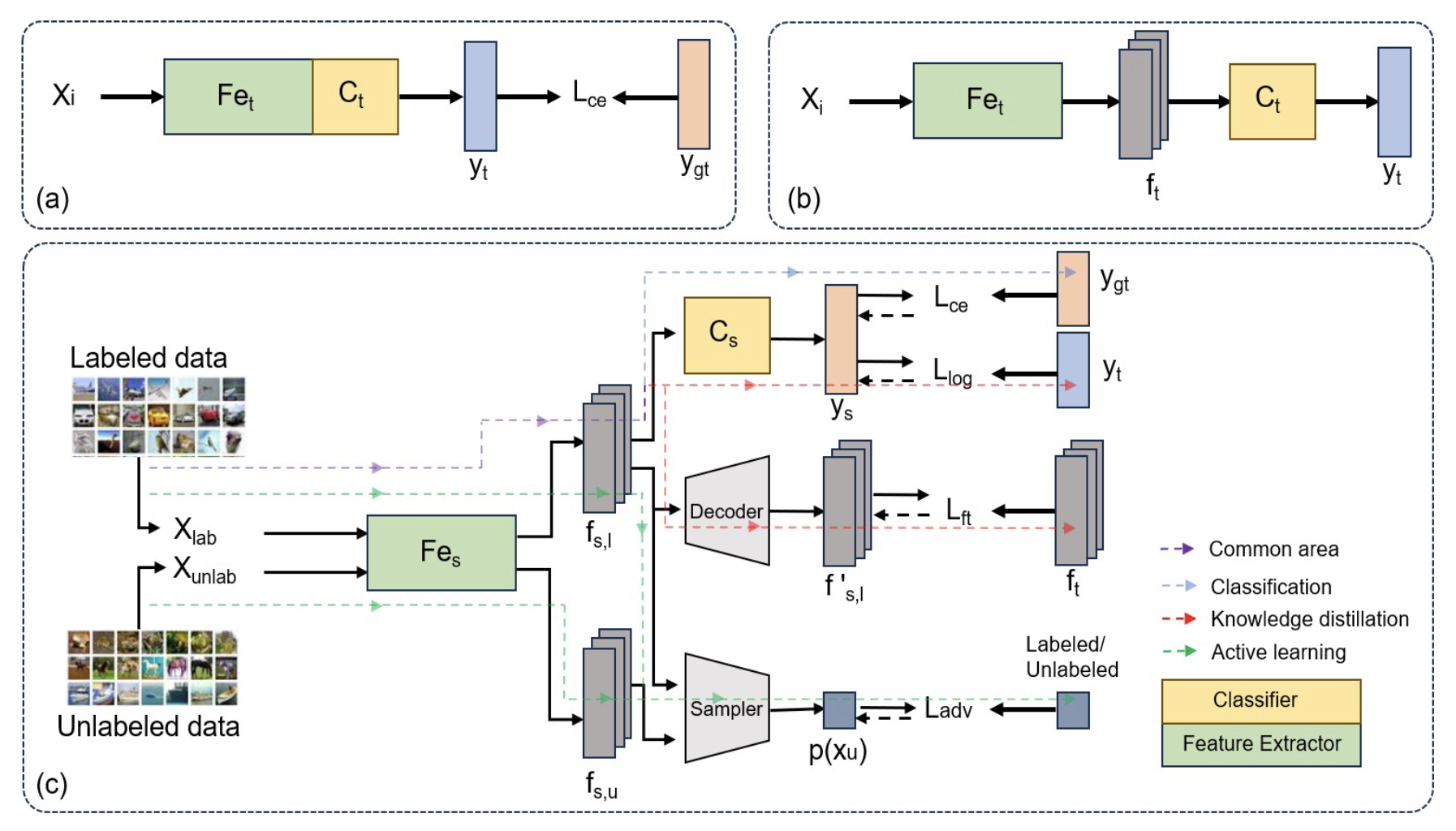 EnCoDe: Enhancing Compressed Deep Learning Models Through Feature—Distillation and Informative Sample SelectionRebati Gaire, Sepehr Tabrizchi, and Arman RoohiIn 2023 International Conference on Machine Learning and Applications (ICMLA), 2023
EnCoDe: Enhancing Compressed Deep Learning Models Through Feature—Distillation and Informative Sample SelectionRebati Gaire, Sepehr Tabrizchi, and Arman RoohiIn 2023 International Conference on Machine Learning and Applications (ICMLA), 2023This paper presents Encode, a novel technique that merges active learning, model compression, and knowledge distillation to optimize deep learning models. The method tackles issues such as generalization loss, resource intensity, and data redundancy that usually impede compressed models’ performance. It actively integrates valuable samples for labeling, thus enhancing the student model’s performance while economizing on labeled data and computational resources. Encode’s utility is empirically validated using SVHN and CIFAR-10 datasets, demonstrating improved model compactness, enhanced generalization, reduced computational complexity, and lessened labeling efforts. In our evaluations, applied to compressed versions of VGGll and AlexNet models, Encode consistently outperforms baselines even when trained with 60% of the total training samples. Thus, it establishes an effective framework for enhancing the accuracy and generalization capabilities of compressed models, which is especially beneficial in situations with limited resources and scarce labeled data.
@inproceedings{gaire2023encode, title = {EnCoDe: Enhancing Compressed Deep Learning Models Through Feature---Distillation and Informative Sample Selection}, author = {Gaire, Rebati and Tabrizchi, Sepehr and Roohi, Arman}, booktitle = {2023 International Conference on Machine Learning and Applications (ICMLA)}, pages = {633--638}, year = {2023}, organization = {IEEE}, google_scholar_id = {zYLM7Y9cAGgC}, doi = {10.1109/ICMLA58977.2023.00093}, } -
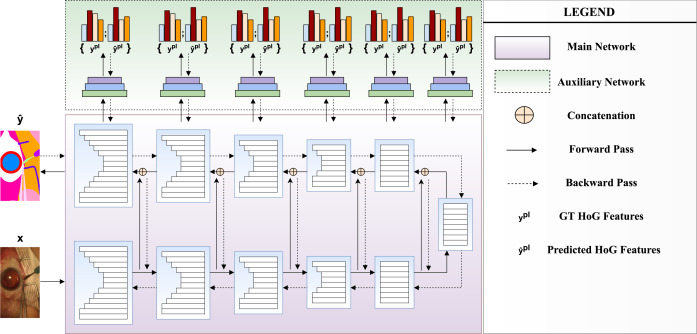 Histogram of oriented gradients meet deep learning: A novel multi-task deep network for 2D surgical image semantic segmentationBinod Bhattarai, Ronast Subedi, Rebati Raman Gaire, and 2 more authorsMedical Image Analysis, 2023
Histogram of oriented gradients meet deep learning: A novel multi-task deep network for 2D surgical image semantic segmentationBinod Bhattarai, Ronast Subedi, Rebati Raman Gaire, and 2 more authorsMedical Image Analysis, 2023We present our novel deep multi-task learning method for medical image segmentation. Existing multi-task methods demand ground truth annotations for both the primary and auxiliary tasks. Contrary to it, we propose to generate the pseudo-labels of an auxiliary task in an unsupervised manner. To generate the pseudo-labels, we leverage Histogram of Oriented Gradients (HOGs), one of the most widely used and powerful hand-crafted features for detection. Together with the ground truth semantic segmentation masks for the primary task and pseudo-labels for the auxiliary task, we learn the parameters of the deep network to minimize the loss of both the primary task and the auxiliary task jointly. We employed our method on two powerful and widely used semantic segmentation networks: UNet and U2Net to train in a multi-task setup. To validate our hypothesis, we performed experiments on two different medical image segmentation data sets. From the extensive quantitative and qualitative results, we observe that our method consistently improves the performance compared to the counter-part method. Moreover, our method is the winner of FetReg Endovis Sub-challenge on Semantic Segmentation organised in conjunction with MICCAI 2021. Code and implementation details are available at: https://github.com/thetna/medical_image_segmentation .
@article{bhattarai2023histogram, title = {Histogram of oriented gradients meet deep learning: A novel multi-task deep network for 2D surgical image semantic segmentation}, author = {Bhattarai, Binod and Subedi, Ronast and Gaire, Rebati Raman and Vazquez, Eduard and Stoyanov, Danail}, journal = {Medical Image Analysis}, volume = {85}, pages = {102747}, year = {2023}, publisher = {Elsevier}, google_scholar_id = {9yKSN-GCB0IC}, } -
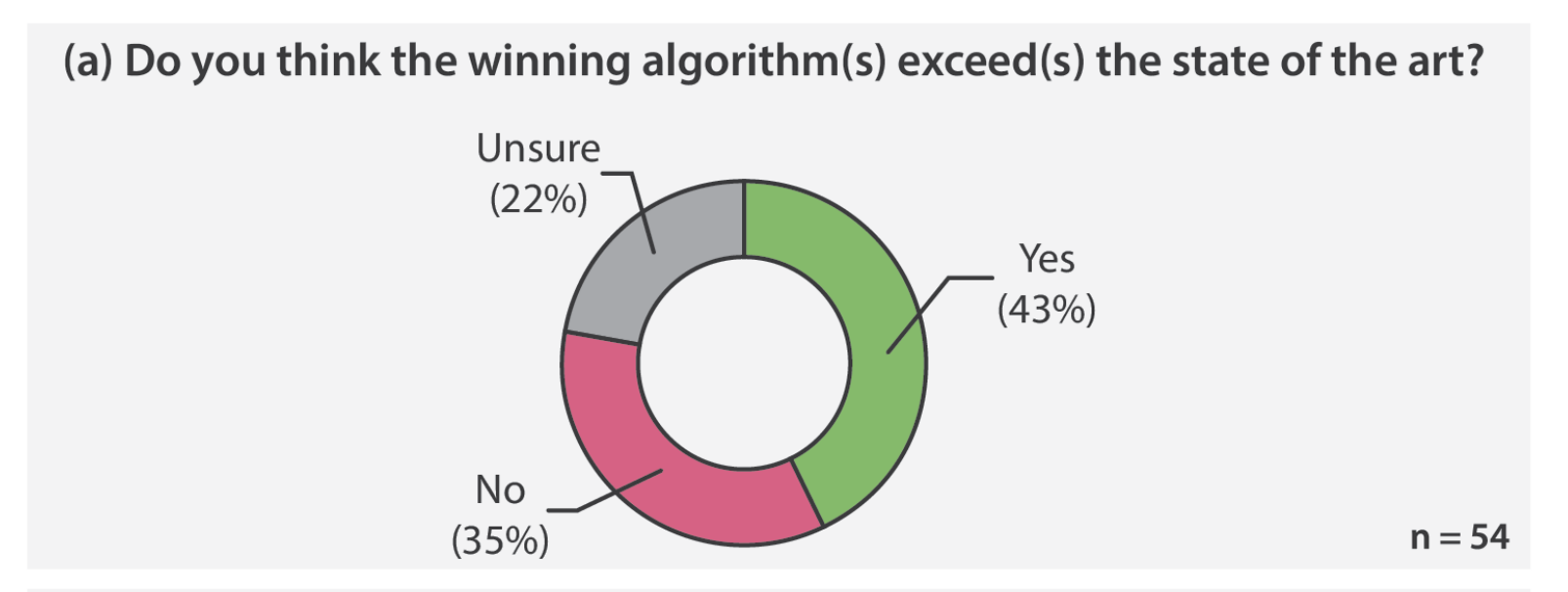 Why is the winner the best?Matthias Eisenmann, Annika Reinke, Vivienn Weru, and 8 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
Why is the winner the best?Matthias Eisenmann, Annika Reinke, Vivienn Weru, and 8 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
@inproceedings{eisenmann2023winner, title = {Why is the winner the best?}, author = {Eisenmann, Matthias and Reinke, Annika and Weru, Vivienn and Tizabi, Minu D and Isensee, Fabian and Adler, Tim J and Ali, Sharib and Andrearczyk, Vincent and Aubreville, Marc and Baid, Ujjwal and others}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages = {19955--19966}, year = {2023}, google_scholar_id = {qjMakFHDy7sC}, } -
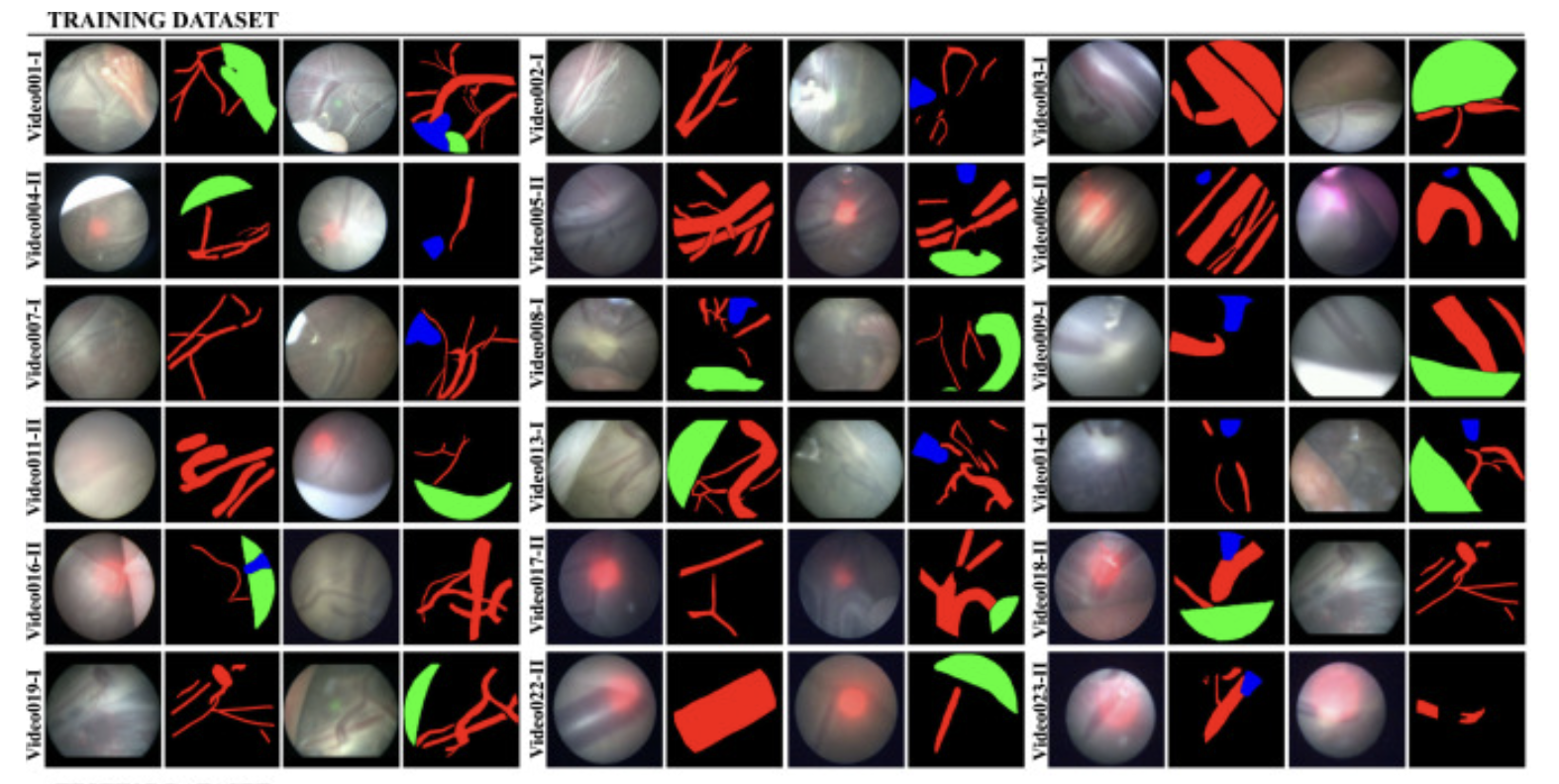 Placental vessel segmentation and registration in fetoscopy: literature review and MICCAI FetReg2021 challenge findingsSophia Bano, Alessandro Casella, Francisco Vasconcelos, and 8 more authorsMedical Image Analysis, 2023
Placental vessel segmentation and registration in fetoscopy: literature review and MICCAI FetReg2021 challenge findingsSophia Bano, Alessandro Casella, Francisco Vasconcelos, and 8 more authorsMedical Image Analysis, 2023Fetoscopy laser photocoagulation is a widely adopted procedure for treating Twin-to-Twin Transfusion Syndrome (TTTS). The procedure involves photocoagulation pathological anastomoses to restore a physiological blood exchange among twins. The procedure is particularly challenging, from the surgeon’s side, due to the limited field of view, poor manoeuvrability of the fetoscope, poor visibility due to amniotic fluid turbidity, and variability in illumination. These challenges may lead to increased surgery time and incomplete ablation of pathological anastomoses, resulting in persistent TTTS. Computer-assisted intervention (CAI) can provide TTTS surgeons with decision support and context awareness by identifying key structures in the scene and expanding the fetoscopic field of view through video mosaicking. Research in this domain has been hampered by the lack of high-quality data to design, develop and test CAI algorithms. Through the Fetoscopic Placental Vessel Segmentation and Registration (FetReg2021) challenge, which was organized as part of the MICCAI2021 Endoscopic Vision (EndoVis) challenge, we released the first large-scale multi-center TTTS dataset for the development of generalized and robust semantic segmentation and video mosaicking algorithms with a focus on creating drift-free mosaics from long duration fetoscopy videos. For this challenge, we released a dataset of 2060 images, pixel-annotated for vessels, tool, fetus and background classes, from 18 in-vivo TTTS fetoscopy procedures and 18 short video clips of an average length of 411 frames for developing placental scene segmentation and frame registration for mosaicking techniques. Seven teams participated in this challenge and their model performance was assessed on an unseen test dataset of 658 pixel-annotated images from 6 fetoscopic procedures and 6 short clips. For the segmentation task, overall baseline performed was the top performing (aggregated mIoU of 0.6763) and was the best on the vessel class (mIoU of 0.5817) while team RREB was the best on the tool (mIoU of 0.6335) and fetus (mIoU of 0.5178) classes. For the registration task, overall the baseline performed better than team SANO with an overall mean 5-frame SSIM of 0.9348. Qualitatively, it was observed that team SANO performed better in planar scenarios, while baseline was better in non-planner scenarios. The detailed analysis showed that no single team outperformed on all 6 test fetoscopic videos. The challenge provided an opportunity to create generalized solutions for fetoscopic scene understanding and mosaicking. In this paper, we present the findings of the FetReg2021 challenge, alongside reporting a detailed literature review for CAI in TTTS fetoscopy. Through this challenge, its analysis and the release of multi-center fetoscopic data, we provide a benchmark for future research in this field.
@article{bano2023placental, title = {Placental vessel segmentation and registration in fetoscopy: literature review and MICCAI FetReg2021 challenge findings}, author = {Bano, Sophia and Casella, Alessandro and Vasconcelos, Francisco and Qayyum, Abdul and Benzinou, Abdesslam and Mazher, Moona and Meriaudeau, Fabrice and Lena, Chiara and Cintorrino, Ilaria Anita and De Paolis, Gaia Romana and others}, journal = {Medical Image Analysis}, pages = {103066}, year = {2023}, publisher = {Elsevier}, google_scholar_id = {d1gkVwhDpl0C}, } -
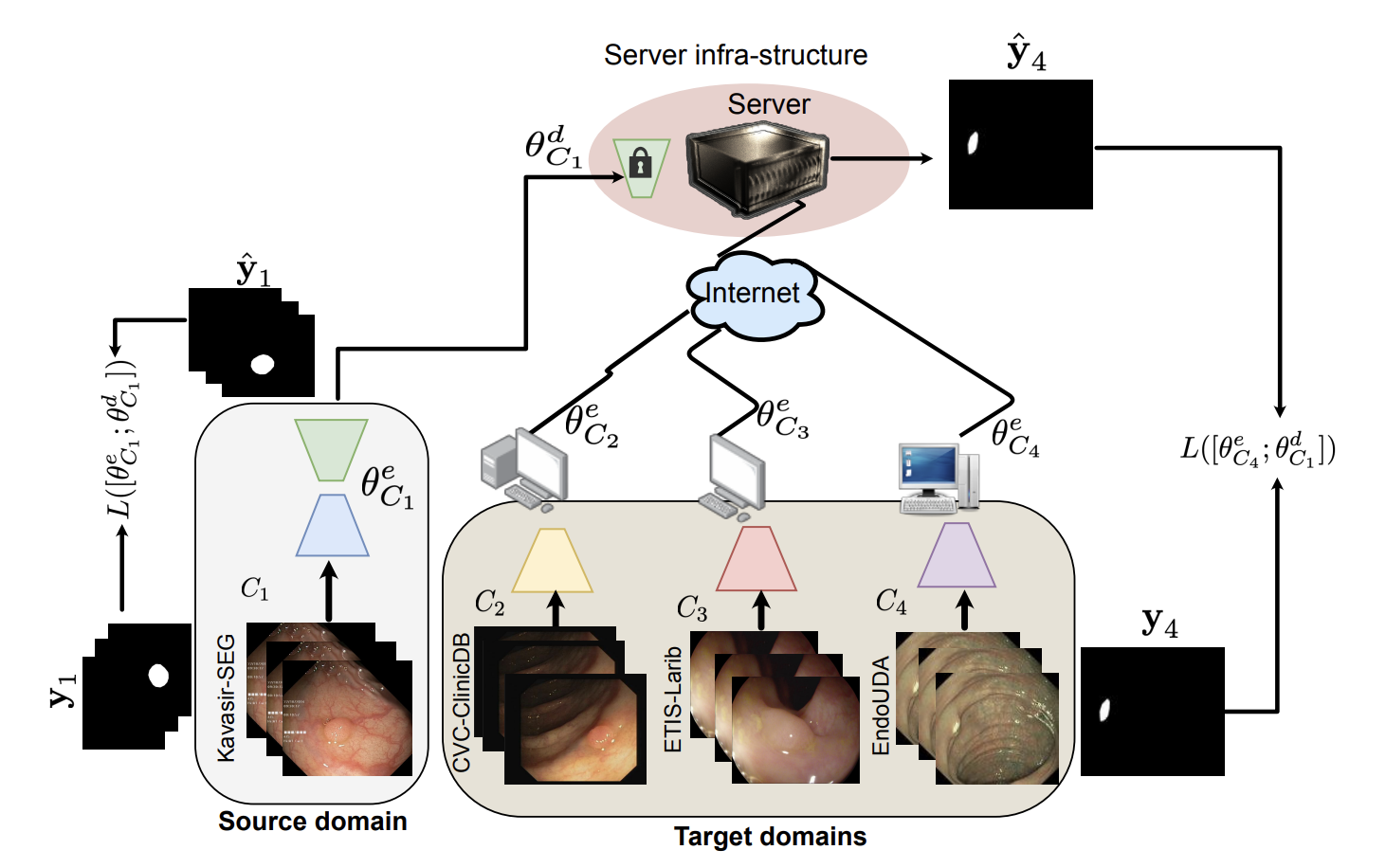 A client-server deep federated learning for cross-domain surgical image segmentationRonast Subedi, Rebati Raman Gaire, Sharib Ali, and 3 more authorsIn MICCAI Workshop on Data Engineering in Medical Imaging, 2023
A client-server deep federated learning for cross-domain surgical image segmentationRonast Subedi, Rebati Raman Gaire, Sharib Ali, and 3 more authorsIn MICCAI Workshop on Data Engineering in Medical Imaging, 2023This paper presents a solution to the cross-domain adaptation problem for 2D surgical image segmentation, explicitly considering the privacy protection of distributed datasets belonging to different centers. Deep learning architectures in medical image analysis necessitate extensive training data for better generalization. However, obtaining sufficient diagnostic and surgical data is still challenging, mainly due to the inherent cost of data curation and the need of experts for data annotation. Moreover, increased privacy and legal compliance concerns can make data sharing across clinical sites or regions difficult. Another ubiquitous challenge the medical datasets face is inevitable domain shifts among the collected data at the different centers. To this end, we propose a Client-server deep federated architecture for cross-domain adaptation. A server hosts a set of immutable parameters common to both the source and target domains. The clients consist of the respective domain-specific parameters and make requests to the server while learning their parameters and inferencing. We evaluate our framework in two benchmark datasets, demonstrating applicability in computer-assisted interventions for endoscopic polyp segmentation and diagnostic skin lesion detection and analysis. Our extensive quantitative and qualitative experiments demonstrate the superiority of the proposed method compared to competitive baseline and state-of-the-art methods. We will make the code available upon the paper’s acceptance.
@inproceedings{subedi2023client, title = {A client-server deep federated learning for cross-domain surgical image segmentation}, author = {Subedi, Ronast and Gaire, Rebati Raman and Ali, Sharib and Nguyen, Anh and Stoyanov, Danail and Bhattarai, Binod}, booktitle = {MICCAI Workshop on Data Engineering in Medical Imaging}, pages = {21--33}, year = {2023}, google_scholar_id = {IjCSPb-OGe4C}, organization = {Springer} } -
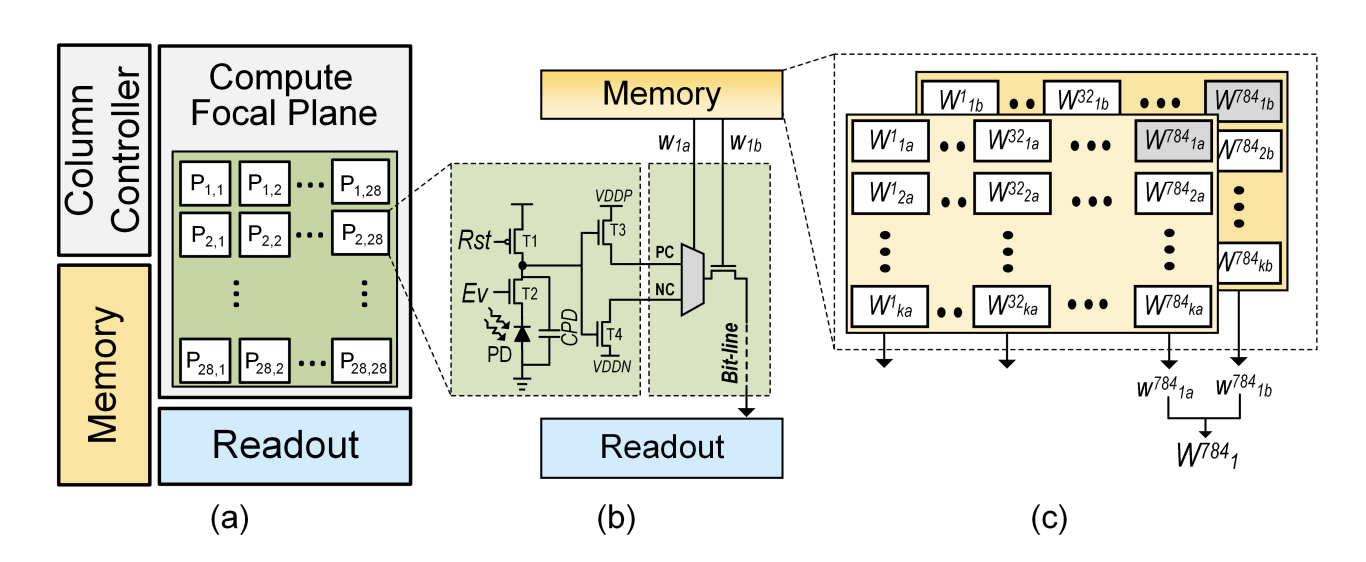 SenTer: A reconfigurable processing-in-sensor architecture enabling efficient ternary MLPSepehr Tabrizchi, Rebati Gaire, Shaahin Angizi, and 1 more authorIn Proceedings of the Great Lakes Symposium on VLSI 2023, 2023
SenTer: A reconfigurable processing-in-sensor architecture enabling efficient ternary MLPSepehr Tabrizchi, Rebati Gaire, Shaahin Angizi, and 1 more authorIn Proceedings of the Great Lakes Symposium on VLSI 2023, 2023Recently, Intelligent IoT (IIoT), including various sensors, has gained significant attention due to its capability of sensing, deciding, and acting by leveraging artificial neural networks (ANN). Nevertheless, to achieve acceptable accuracy and high performance in visual systems, a power-delay-efficient architecture is required. In this paper, we propose an ultra-low-power processing in-sensor architecture, namely SenTer, realizing low-precision ternary multi-layer perceptron networks, which can operate in detection and classification modes. Moreover, SenTer supports two activation functions based on user needs and the desired accuracy-energy trade-off. SenTer is capable of performing all the required computations for the MLP’s first layer in the analog domain and then submitting its results to a co-processor. Therefore, SenTer significantly reduces the overhead of analog buffers, data conversion, and transmission power consumption by using only one ADC. Additionally, our simulation results demonstrate acceptable accuracy on various datasets compared to the full precision models.
@inproceedings{tabrizchi2023senter, title = {SenTer: A reconfigurable processing-in-sensor architecture enabling efficient ternary MLP}, author = {Tabrizchi, Sepehr and Gaire, Rebati and Angizi, Shaahin and Roohi, Arman}, booktitle = {Proceedings of the Great Lakes Symposium on VLSI 2023}, pages = {497--502}, year = {2023}, google_scholar_id = {UeHWp8X0CEIC}, }






2022
-
 GAN-Based Two-Step Pipeline for Real-World Image Super-ResolutionRebati Raman Gaire, Ronast Subedi, Ashim Sharma, and 3 more authorsIn ICT with Intelligent Applications: Proceedings of ICTIS 2021, Volume 1, 2022
GAN-Based Two-Step Pipeline for Real-World Image Super-ResolutionRebati Raman Gaire, Ronast Subedi, Ashim Sharma, and 3 more authorsIn ICT with Intelligent Applications: Proceedings of ICTIS 2021, Volume 1, 2022Mostly, the prior works on single image super-resolution are dependent on high-resolution image and their bicubically downsampled low-resolution image pairs. Such methods have achieved outstanding results in single image super-resolution. Yet, these methods struggle to generalize real-world low-resolution images. Real-world low-resolution images have large varieties of degradation, and modeling these degradation accurately is a challenging task. Although some works have been proposed to address this problem, their results still lack fine perceptual details. Here, we use a GAN-based two-step pipeline to address this challenging problem of real-world image super-resolution. At first, we train a GAN network that transforms real-world low-resolution images to a space of bicubic images of the same size. This network is trained on real-world low-resolution images as input and bicubically downsampled version of their corresponding high-resolution images as ground truth. Then, we employ the nESRGAN+ network trained on bicubically downsampled low-resolution and high-resolution image pairs to super-resolve the transformed bicubic alike images. Hence, the first network transforms the wide varieties of degraded images into the bicubic space, and the second network upscales the first output by the factor of four. We show the effectiveness of this work by evaluating its output on various benchmark test datasets and comparing our results with other works. We also show that our work outperforms prior works in both qualitative and quantitative comparison. We have published our source code and trained models here for further research and improvement.
@inproceedings{gaire2022gan, title = {GAN-Based Two-Step Pipeline for Real-World Image Super-Resolution}, author = {Gaire, Rebati Raman and Subedi, Ronast and Sharma, Ashim and Subedi, Shishir and Ghimire, Sharad Kumar and Shakya, Subarna}, booktitle = {ICT with Intelligent Applications: Proceedings of ICTIS 2021, Volume 1}, pages = {763--772}, year = {2022}, organization = {Springer}, google_scholar_id = {u5HHmVD_uO8C}, }
